The Challenge
Smallholder irrigation in sub-Saharan Africa is vital for food security and rural livelihoods, yet nobody knows exactly where it is. Government statistics are incomplete, and traditional surveys are expensive and slow.
Satellite imagery offers hope—we can see the Earth at high resolution from space. But detecting scattered, small-scale irrigation plots in complex, diverse landscapes is surprisingly difficult.
Why is it hard?
- Scale: Plots are often tiny (< 1 hectare), requiring very high-resolution imagery
- Heterogeneity: Mixed cropland, natural vegetation, and water create confusion
- Temporal dynamics: Irrigation patterns shift with seasons and cropping cycles
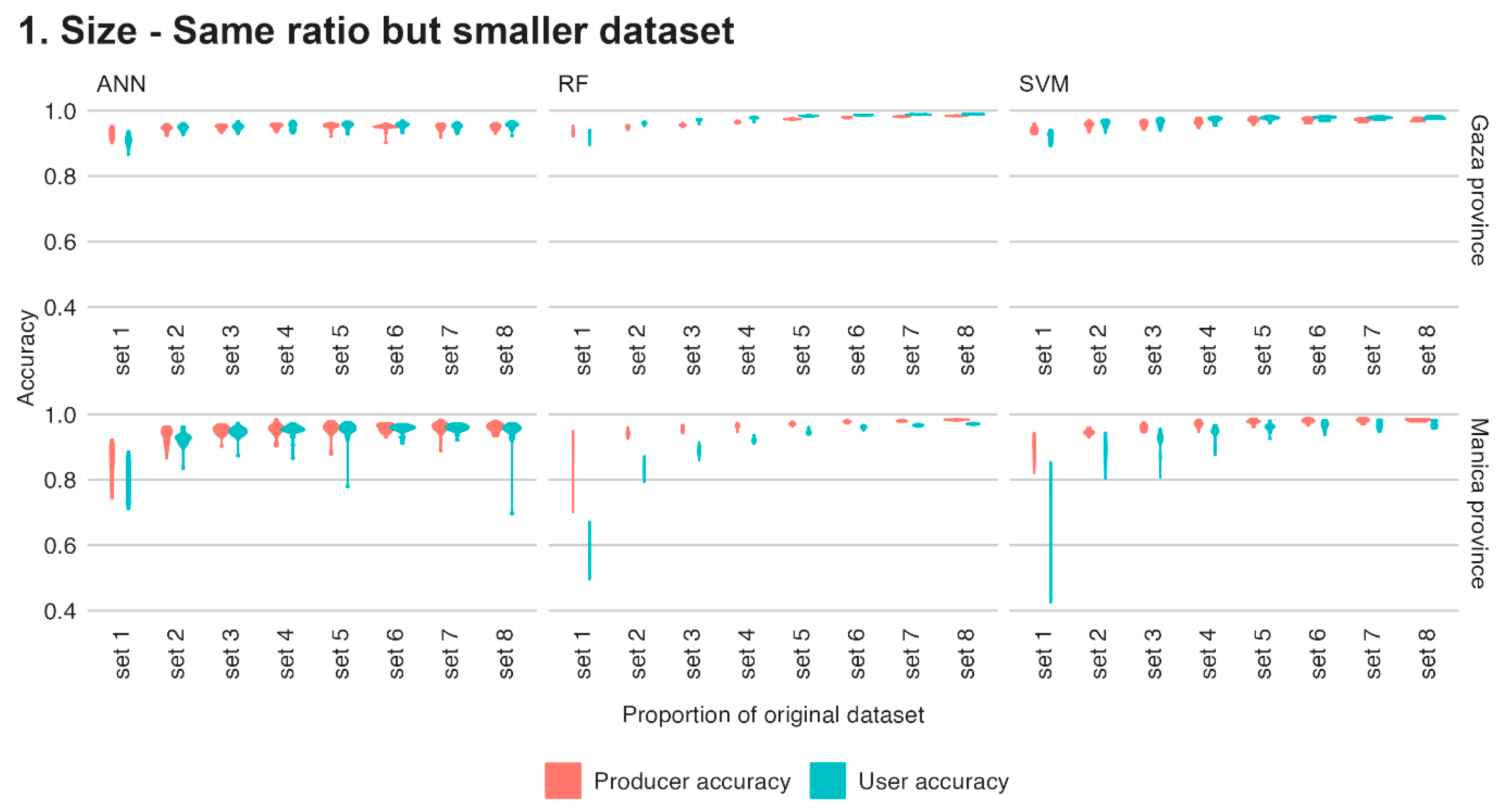
- Data scarcity: Limited training data in most African regions
- Methodological choices: Different algorithms, temporal windows, and parameters yield different results
This raises a critical question: How do we know if our satellite-based maps are actually detecting real irrigation?